
Abstract
Utilities and energy operators manage high-critical assets, where unplanned failures pose safety risks, service disruptions, and volatile maintenance expenditures. Corrective maintenance restores equipment after faults occur, but it also introduces uncertainty: failures are bursty, costs are heavy-tailed, and planning often depends on rough averages. Predictive maintenance (PdM) uses operational and condition data to anticipate failures earlier, enabling smarter interventions and more reliable budgeting than “fix after failure” approaches. In industrial PdM, the practical success factors are rarely “just the algorithm”; they are data integration, robust preprocessing, disciplined validation, and operational deployment into maintenance and CAPEX planning workflows.
This case study describes how a UAE-based utility operator implemented a machine-learning PdM and cost-forecasting capability for its energy assets, with quantified optimisation targets of 10–20%.
Machine learning algorithms in predictive maintenance (what works and why)
PdM typically covers three tasks: (1) anomaly/fault detection, (2) fault diagnosis/classification, and (3) prognostics/forecasting (failure timing and/or cost). Common approaches include logistic regression for interpretable classification, SVM/random forest for condition diagnosis and RUL-style estimation on structured datasets, and deep learning (CNN/RNN/LSTM, including autoencoders) for time-series anomaly detection where temporal patterns matter.
In practice, PdM success depends less on an exotic model and more on execution: robust preprocessing/feature engineering (noise, missingness, time alignment, tuning), explainability/traceability for operational trust, and scalability from pilots to fleet/portfolio deployment.
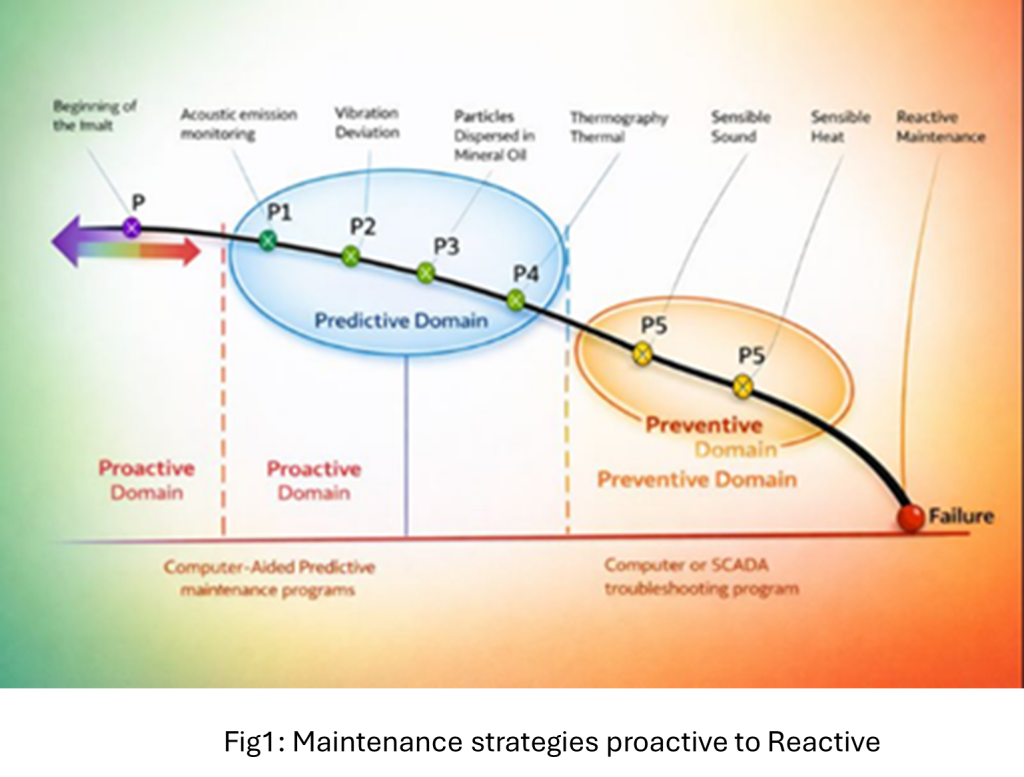
Challenges and opportunities (energy sector lens)
Energy and utility assets are data-rich but operationally noisy: multiple plants, different control strategies, seasonal regimes, and heterogeneous equipment classes. Major adoption blockers include incomplete datasets (inconsistent tags and hierarchy mapping across ERP/EAM and OT sources), model opacity (slowing operational trust), and false alarms (which can overwhelm maintenance teams if thresholds and alert logic are not engineered carefully). The opportunity is clear: once PdM outputs become a repeatable digital product embedded in work planning and CAPEX governance, they improve both reliability and financial control.
The case study: a UAE based utility’s PdM + cost forecasting system
Starting point: the data foundation
The operator consolidated long-horizon maintenance and asset data covering ~65K assets and ~77K work orders, with a multi-million cost history and a 2004–2022 window. A structured data-quality programme improved assessed quality from 38% (pre-cleaning) to 54% (post-cleaning), with a roadmap to ~80% through further remediation, including OT integration and functional tag mapping.
Method (end‑to‑end lifecycle)
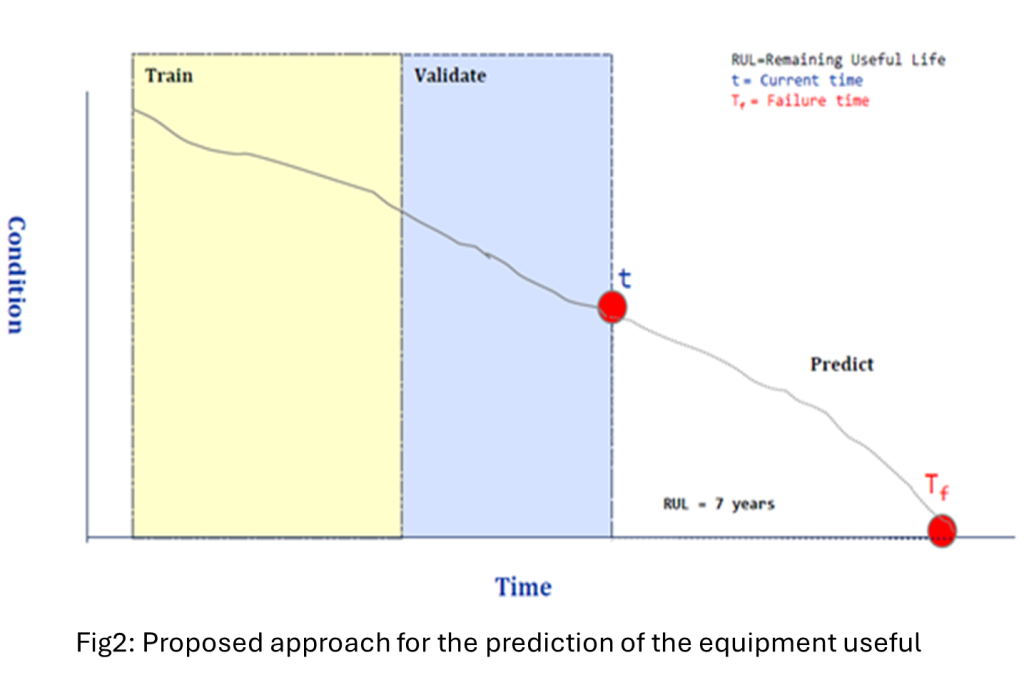
The implementation followed a standard PdM lifecycle (data acquisition → preprocessing → model selection → training/validation → deployment) and was productised on an integrated data model/ETL layer using hierarchical equipment and work-order structures to unify ERP and OT sources (SAP, JDE and OT) under a single data standard. Delivery was operationalised via five ETL pipelines and 16 workflows with scheduled refresh to staging/production databases, making outputs repeatable and auditable rather than one-off analyses.
For modelling, the utility used multi-model architecture (three ML models aligned to different equipment data types) to reflect varying feature availability and failure behaviour across equipment classes. The core forecasting engine applied non-linear regression in the gradient-boosting family to estimate corrective-maintenance cost per year of time-in-service using contextual covariates (e.g., manufacturer, rating, sub-type, plant type), then aggregated equipment-level outputs into plant and business-unit views for fleet/portfolio decision-making. Training/validation achieved plant-level R² of 77.13%, indicating a strong fit for cost forecasting in a heterogeneous industrial environment.
Feature engineering focused on time-in-service/age (from commissioning and work-order timestamps), failure history (event counts, time since last failure, cumulative cost), and context (equipment group/sub-group, capacity bands, manufacturer, plant type). Costs were standardised via inflation/price-index adjustments and cross-plant distribution alignment to reduce purchasing/accounting bias; for selected assets (e.g., chillers), proof-of-concept work linked operational indicators (e.g., COP, load) to degradation and remaining-life thinking to support deeper OT-driven PdM in later phases.
Deployment was treated as a first-class deliverable: an end-user application and dashboards were delivered for CM cost estimation with scheduled execution, governed refresh, and separate test/production environments (via the same five pipelines/16 workflows). Decision-grade outputs were enabled by (1) hierarchical data modelling for consistent cross-plant comparisons and (2) replacement logic with configurable useful-life rules to simulate cycles and forecast failure costs under “new equipment” assumptions—linking ML forecasts directly to CAPEX and lifecycle planning.
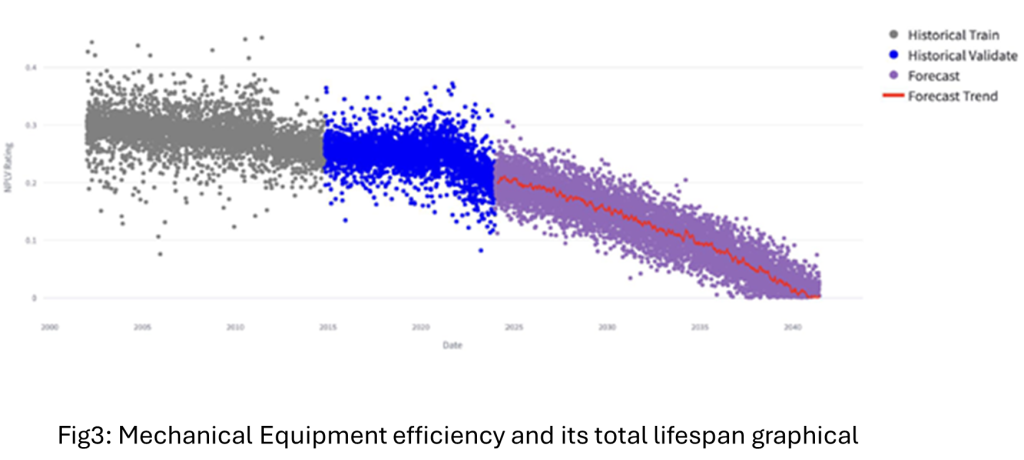
Impact: cost optimisation and governance (what changed)
The programme was positioned as both a PdM initiative and a costing-model enhancement. The stated optimisation targets were 10–20% for corrective-maintenance module enhancement and for the fully digitised costing model, including scenario planning and incorporation of ML forecasts.
In practice, the ML system improved forecasting of future failure repair costs (reducing under- and over-estimation risk) and strengthened budgeting and cash-flow planning. Portfolio standardisation via unified datasets, scheduled pipelines and reusable dashboards turned the analytics into a scalable internal software product rather than an isolated study, enabling more consistent maintenance planning and CAPEX governance across sites.
Key takeaways for energy and utilities teams
For energy and utilities teams, a few lessons stand out. First, treat PdM as a digital product—not a model—by prioritising pipelines, governance, scheduled runs, and user-facing tools. Second, use multi-model architectures when feature availability differs across equipment families; fleet reality often beats theoretical elegance. Third, embed lifecycle logic (useful life and replacement simulation) so PdM connects directly to CAPEX governance and scenario planning. Finally, treat data quality as a measurable programme: the 38% → 54% uplift plus a defined roadmap (~80%) is what enables long-term reliability at portfolio scale.
About the Author:

Muhammad Mansoor Ansar works in the utilities sector on data engineering, applied machine learning, and lifecycle cost modelling to support O&M performance, predictive maintenance and CAPEX decision governance. Organisational names and certain technical details have been anonymised for confidentiality. This piece is vendor-neutral and reflects experience across Gulf utility environments.
References (external, for concepts only)
Ajayi, O. O., Kurien, A. M., Djouani, K., & Dieng, L. (2025). A proactive predictive model for machine failure forecasting. Machines, 13(8), 663.
Singh, O., Hire, M., Patel, O., & Singh, S. (2025). Machine failure prediction using machine learning: A multi-stage approach for predictive maintenance. International Journal of Scientific Research and Engineering Development, 8(2), 510–516.
Scrivano, A. (2024). Role of machine learning in predictive maintenance of industrial machinery. TechRxiv preprint.
Akyaz, T., & Engin, D. (2024). Machine learning-based predictive maintenance system for artificial yarn machines. IEEE Access.
Neural Concept. (n.d.). Predictive maintenance machine learning: A practical guide.
OECD. (2023). Guidance on responsible AI and governance in enterprise contexts (policy report).